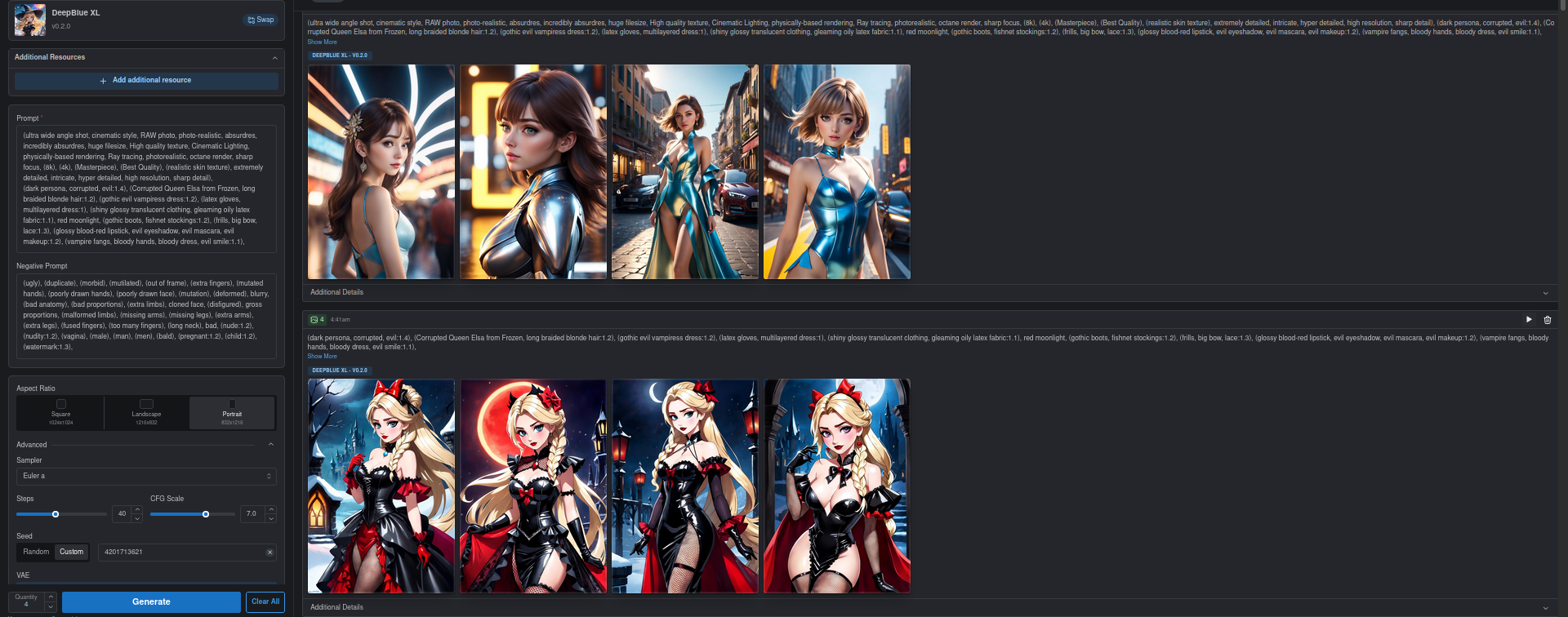
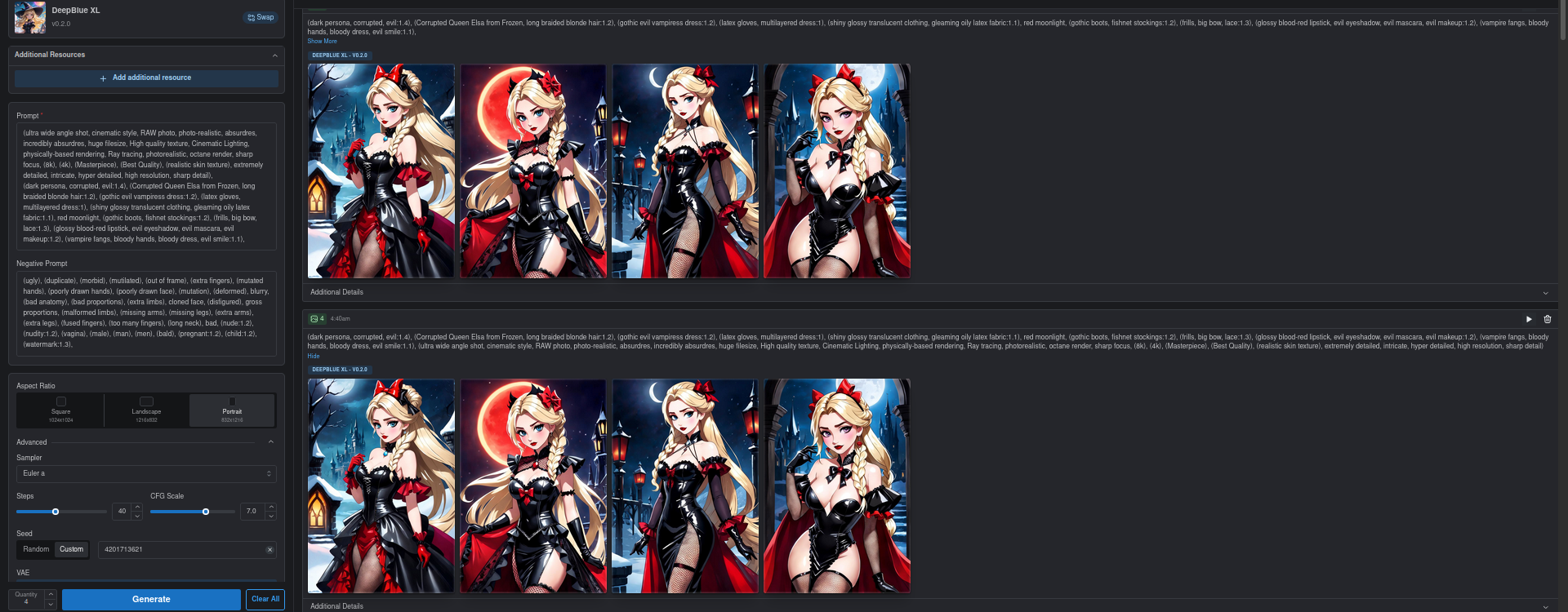
When using XL Models, the onsite generator only aknowledges the prompt up to a certain length.
Screenshots showcase results using same seed but different prompts.
Adding a bunch of tokens to the end of the prompt resulted in the exact same images being generated. Meanwhile, adding them to the front caused the effect of the original prompt to be completely eliminated.
Conclusion: Only a fixed number of tokens are used for the generation request and the rest are ignored completely. This only happens when using XL models, non-XL models behave as expected.
Please authenticate to join the conversation.
Upvoters
Status
Awaiting Dev Review
Board
💡 Feature Request
Date
Over 2 years ago
Author

Anonimous1234567890
Subscribe to post
Get notified by email when there are changes.
Upvoters
Status
Awaiting Dev Review
Board
💡 Feature Request
Date
Over 2 years ago
Author
Anonimous1234567890
Subscribe to post
Get notified by email when there are changes.